Refactoring Go4Data - using Interfaces and Benchmarks
A step-by-step guide on how one can use interfaces in Go to refactor and make your code base very modular
by Percy Bolmér, February 4, 2021
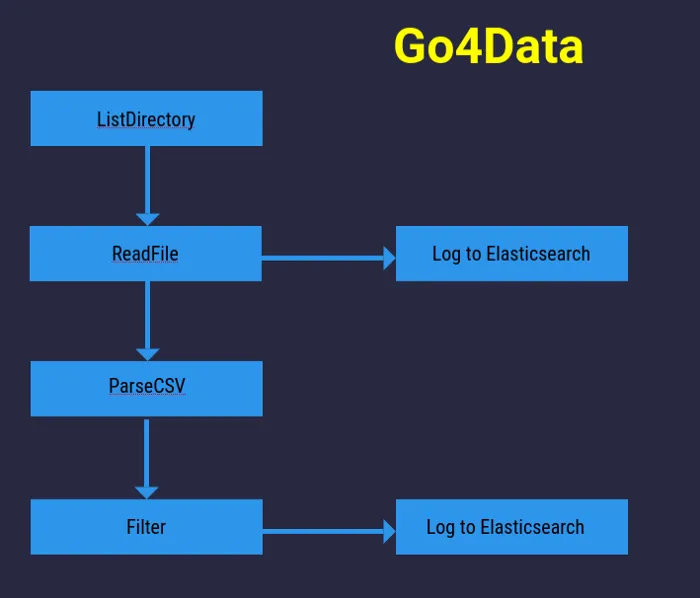
In this article, I will cover how I used the power of the Golang interface to replace a major piece in Go4Data . We will also use benchmarks to compare to old solution to the new solution.
I want the article to focus on HOW to use interfaces properly, along with benchmarks rather than the code I’m changing. Since we will change a lot of code, I don’t expect you to code this yourself, but rather try to embrace the process and mindset of using the interfaces.
Let’s begin by explaining what Go4Data is, or what I want it to become. Go4Data is a data processing tool. It’s focused on processing data and is currently very much a work in progress. The idea is that you can set up inputs, like a Redis queue, or files in a directory. Then you can pass the data onto the next data processor by a Pub/Sub engine. The idea came from after my 100th project having to read CSV files and put them into a database after performing filtering and transformation on the data.
This is all done by a YAML configuration file that Go4Data loads, no coding needed.
The part that we will refactor today is the Pub/Sub system that Go4Data uses. During the development, I created a custom in-memory pub/sub system. This works fine, but It’s not very scalable since it relies on the memory used by the current application. Allowing users to configure the Pub/Sub engine used by Go4Data by creating a Pub/Sub interface would be very cool, so let’s do that. I will also implement a Redis implementation of the interface.
When the Redis implementation is complete we will benchmark both to see which performs best. If your unfamiliar with how Redis works with Pub/Sub read my other article.
In the end, we will allow users to switch between Go4Datas custom Pub/Sub and Redis by simply calling the method NewEngine. The gist below shows how to perform the change.
Changing between Redis and Default will be a simple configuration.
// This shows how to change the whole Go4Data to use Redis instead
_, err := pubsub.NewEngine(WithRedisEngine(&redis.Options{
Addr: "localhost:6379",
Password: "",
DB: 0,
})
// This is how we would change back to DefaultEngine
_, err := pubsub.NewEngine(WithDefaultEngine(2))Start by reviewing what currently exists
So the first thing I want to do is take a look at the current implementation, we will try to make the interface fit right into this so that we can allow users to swap the whole Pub/Sub engine out without modifying any other code.
The current Pub/Sub engine exposes a few global methods that the whole Go4Data uses to Publish and Subscribe the data. The methods are Publish, PublishTopics, and Subscribe . So if we use these 3 methods in the interface that we will create we should be able to replace the whole logic without breaking the rest of the packages.
Create the Interface
I will take those 3 methods and extract them into an interface called Engine. The engine will be used exposed by a public API with three identical methods. This allows users to reconfigure the Engine used very easily without breaking all other packages.
I will want the old implementation to be the default when running Go4Data because we don’t want to force the users to have Redis installed. So we will also have to create a default struct that will implement the Engine interface.
This is the interface that we will need in Go4Data.
// Engine is a interface that declares what methods a pub/sub engine needs in Go4Data
type Engine interface {
Publish(key string, payloads ...payload.Payload) []PublishingError
PublishTopics(topics []string, payloads ...payload.Payload) []PublishingError
Subscribe(key string, pid uint, queueSize int) (*Pipe, error)
}Expose the needed methods globally
Since the rest of the packages in Go4Data relies on the methods to be available I will create some wrapper functions that will match the API, but they will only call the real methods of the underlying selected Engine to run.
Since we exposing methods that will rely on the interface implementations we will create soon, we need to create a init function that runs as soon as the package is imported. Here we will create a DefaultEngine object so Go4Data doesn’t crash if an Engine is not set.
The complete PubSub code, exposing the methods and wrapping the engine.
package pubsub
import "github.com/percybolmer/go4data/payload"
// Engine is a interface that declares what methods a pub/sub engine needs in Go4Data
type Engine interface {
Publish(key string, payloads ...payload.Payload) []PublishingError
PublishTopics(topics []string, payloads ...payload.Payload) []PublishingError
Subscribe(key string, pid uint, queueSize int) (*Pipe, error)
}
// DialOptions are used to configure with variable amount of Options
type DialOptions func(Engine) (Engine, error)
// engine is the currently selected Engine to use for Pub/Sub.
var engine Engine
func init() {
// Set DefaultEngine as a Default on INIT to avoid API calls from crashing
NewEngine(WithDefaultEngine(2))
}
// NewEngine is used to startup a new Engine based on the Options used
func NewEngine(opts ...DialOptions) (Engine, error) {
var e Engine
// ForEach Option passed in run the configuration
for _, opt := range opts {
new, err := opt(e)
if err != nil {
return nil, err
}
e = new
}
return e, nil
}
// Subscribe will use the currently selected Pub/Sub engine
// And subscribe to a topic
func Subscribe(key string, pid uint, queueSize int) (*Pipe, error) {
return engine.Subscribe(key, pid, queueSize)
}
// Publish is used to publish payloads onto the currently selected Pub/Sub engine
func Publish(key string, payloads ...payload.Payload) []PublishingError {
return engine.Publish(key, payloads...)
}
// PublishTopics will push payloads onto many Topics
func PublishTopics(topics []string, payloads ...payload.Payload) []PublishingError {
return engine.PublishTopics(topics, payloads...)
}This is how the Pub/Sub will look like, it will expose the API to the rest of the packages, so it won’t crash when we change the underlying Pub/Sub engine.
Notice how I’ve created an engine variable that has the type Engine Interface ? This is the variable that we will reconfigure when the users selects Engine, and It’s also the variable that we call the methods from whenever the API methods are called. This allows us to maintain global methods to the rest of the Go4Data packages, but easily switch the logic of the calls.
Implementing the DefaultEngine
The DefaultEngine is the old implementation I used during my development. The full code is long, you can scroll past it if you want. What we will do is take all the methods that exist in it, and instead make them method receivers on a struct called DefaultEngine.
What’s important here is that we will want to make sure DefaultEngine implements the Engine interface. If it does, we should be able to start using it in the whole application right away. This is the beauty of interfaces, as long as we match the API defined in them, we can switch them in and out with new logic very easily.
This is the Old Pub/Sub engine I used, it’s hard coded and hard to change without breaking things.
package pubsub
import (
"errors"
"sync"
"time"
"github.com/percybolmer/go4data/payload"
)
// Topics is a container for topics that has been created.
// A topic is automatically created when a Processor registers as a Subscriber to it
var Topics sync.Map
var (
//ErrTopicAlreadyExists is thrown when running NewTopic on a topic that already exists
ErrTopicAlreadyExists = errors.New("this topic does already exist, cannot create a duplicate topic")
//ErrPidAlreadyRegistered is thrown when trying to publish/subscribe with a processor already publishing/subscribing on a certain topic
ErrPidAlreadyRegistered = errors.New("the pid is already Registered, duplicate Pub/Subs not allowed")
//ErrNoSuchTopic is a error that can be thrown when no topic is found
ErrNoSuchTopic = errors.New("the topic key you search for does not exist")
//ErrNoSuchPid is when no Pid in a topic is found
ErrNoSuchPid = errors.New("no such pid was found on this topic")
//ErrIsNotTopic is when something else than a topic has been loaded in a map
ErrIsNotTopic = errors.New("the item stored in this key is not a topic")
//ErrProcessorQueueIsFull is when a Publisher is trying to publish to a queue that is full
ErrProcessorQueueIsFull = errors.New("cannot push new payload since queue is full")
//ErrTopicBufferIsFull is when a Publisher is trying to publish to a Topic that has a full buffer
ErrTopicBufferIsFull = errors.New("cannot push new payload since topic queue is full")
//IDCounter is used to make sure no Topic are generated with a ID that already exists
IDCounter uint = 1
)
// Init will create the Topic register
func init() {
go func() {
timer := time.NewTicker(2 * time.Second)
for {
select {
case <-timer.C:
DrainTopicsBuffer()
}
}
}()
}
// Topic is a topic that processors can publish or subscribe to
type Topic struct {
// Key is a string value of the topic
Key string
// ID is a unique ID
ID uint
// Subscribers is a datapipe to all processors that has Subscribed
Subscribers []*Pipe
// Buffer is a data pipe containing our Buffer data. It will empty as soon as a subscriber registers
Buffer *Pipe
sync.Mutex
}
// PublishingError is a custom error that is used when reporting back errors when trying to publish
// The reason for it is because we dont want a single Pipe to block all other pipes
type PublishingError struct {
Err error
// Pid is the processor ID
Pid uint
// Tid is the topic ID
Tid uint
Payload payload.Payload
}
// Error is used to be part of error interface
func (pe PublishingError) Error() string {
return pe.Err.Error()
}
// newID is used to generate a new ID
func newID() uint {
IDCounter++
return IDCounter - 1
}
// NewTopic will generate a new Topic and assign it into the Topics map, it will also return it
func NewTopic(key string) (*Topic, error) {
if TopicExists(key) {
return nil, ErrTopicAlreadyExists
}
t := &Topic{
Key: key,
ID: newID(),
Subscribers: make([]*Pipe, 0),
Buffer: &Pipe{
Flow: make(chan payload.Payload, 1000),
},
}
Topics.Store(key, t)
return t, nil
}
// TopicExists is used to find out if a topic exists
// will return true if it does, false if not
func TopicExists(key string) bool {
if _, ok := Topics.Load(key); ok {
return true
}
return false
}
// getTopic is a help util that does the type assertion for us so we dont have to repeat
func getTopic(key string) (*Topic, error) {
t, ok := Topics.Load(key)
if !ok {
return nil, ErrNoSuchTopic
}
topic, ok := t.(*Topic)
if !ok {
return nil, ErrIsNotTopic
}
return topic, nil
}
// Subscribe will take a key and a Pid (processor ID) and Add a new Subscription to a topic
// It will also return the topic used
func Subscribe(key string, pid uint, queueSize int) (*Pipe, error) {
top, err := NewTopic(key)
if errors.Is(err, ErrTopicAlreadyExists) {
// Topic exists, see if PID is not duplicate
topic, err := getTopic(key)
if err != nil {
return nil, err
}
for _, sub := range topic.Subscribers {
if sub.Pid == pid {
return nil, ErrPidAlreadyRegistered
}
}
top = topic
}
// Topic is new , add subscription
sub := NewPipe(key, pid, queueSize)
top.Lock()
top.Subscribers = append(top.Subscribers, sub)
top.Unlock()
return sub, nil
}
// Unsubscribe will remove and close a channel related to a subscription
func Unsubscribe(key string, pid uint) error {
if !TopicExists(key) {
return ErrNoSuchTopic
}
topic, err := getTopic(key)
if err != nil {
return err
}
topic.Lock()
defer topic.Unlock()
pipeline, err := removePipeIfExist(key, pid, topic.Subscribers)
if err != nil {
return err
}
if pipeline != nil {
topic.Subscribers = pipeline
}
return nil
}
// removePipeIfExist is used to delete a index from a pipe slice and return a new slice without it
func removePipeIfExist(key string, pid uint, pipes []*Pipe) ([]*Pipe, error) {
for i, p := range pipes {
if p.Pid == pid {
close(p.Flow)
pipes[i] = pipes[len(pipes)-1]
return pipes[:len(pipes)-1], nil
}
}
return nil, ErrNoSuchPid
}
// DrainTopicsBuffer will itterate all topics and drain their buffer if there is any subscribers
func DrainTopicsBuffer() {
Topics.Range(func(key, value interface{}) bool {
top, ok := value.(*Topic)
if !ok {
return ok
}
top.Lock()
defer top.Unlock()
xCanReceive := len(top.Subscribers)
for len(top.Buffer.Flow) > 0 {
// If no subscriber can Receive more data, stop draining
if xCanReceive == 0 {
break
}
payload := <-top.Buffer.Flow
for _, sub := range top.Subscribers {
select {
case sub.Flow <- payload:
// Managed to send item
default:
// The pipe is full
xCanReceive--
}
}
}
return true
})
}
// Publish is used to publish a payload onto a Topic
// If there is no Subscribers it will push the Payloads onto a Topic Buffer which will be drained as soon
// As there is a subscriber
func Publish(key string, payloads ...payload.Payload) []PublishingError {
var errors []PublishingError
var top *Topic
if TopicExists(key) {
topic, err := getTopic(key)
if err != nil {
return append(errors, PublishingError{
Err: err,
Payload: nil,
})
}
top = topic
} else {
top, _ = NewTopic(key)
}
// If Subscribers is empty, add to Buffer
top.Lock()
defer top.Unlock()
for _, payload := range payloads {
if len(top.Subscribers) == 0 {
select {
case top.Buffer.Flow <- payload:
// Managed to send item
default:
// The pipe is full
errors = append(errors, PublishingError{
Err: ErrTopicBufferIsFull,
Payload: payload,
Tid: top.ID,
})
}
} else {
for _, sub := range top.Subscribers {
select {
case sub.Flow <- payload:
// Managed to send
continue
default:
// This Subscriber queue is full, return an error
// We Could send items to the Buffer top.Buffer.Flow <- payload
// But we would need a way of Knowing what Subscriber has gotten What payload to avoid resending
// It to all Subscribers
errors = append(errors, PublishingError{
Err: ErrProcessorQueueIsFull,
Pid: sub.Pid,
Tid: top.ID,
Payload: payload,
})
}
}
}
}
return errors
}
// PublishTopics is used to publish to many topics at once
func PublishTopics(topics []string, payloads ...payload.Payload) []PublishingError {
var errors []PublishingError
for _, topic := range topics {
t := topic
errs := Publish(t, payloads...)
if errs != nil {
errors = append(errors, errs...)
}
}
if len(errors) == 0 {
return nil
}
return errors
}
So replacing all the code in the old engine and instead of making sure it’s implementing the interface is easy, we just add a simple struct and make all methods part of the struct.
Adding method receivers to the DefaultEngine struct to make it part of the Engine interface
// Package pubsub contains defaultEngine is the default built-in Channel based engine
// used to pubsub
package pubsub
import (
"errors"
"sync"
"time"
"github.com/percybolmer/go4data/payload"
)
var (
//ErrTopicAlreadyExists is thrown when running NewTopic on a topic that already exists
ErrTopicAlreadyExists = errors.New("this topic does already exist, cannot create a duplicate topic")
//ErrPidAlreadyRegistered is thrown when trying to publish/subscribe with a processor already publishing/subscribing on a certain topic
ErrPidAlreadyRegistered = errors.New("the pid is already Registered, duplicate Pub/Subs not allowed")
//ErrNoSuchTopic is a error that can be thrown when no topic is found
ErrNoSuchTopic = errors.New("the topic key you search for does not exist")
//ErrNoSuchPid is when no Pid in a topic is found
ErrNoSuchPid = errors.New("no such pid was found on this topic")
//ErrIsNotTopic is when something else than a topic has been loaded in a map
ErrIsNotTopic = errors.New("the item stored in this key is not a topic")
//ErrProcessorQueueIsFull is when a Publisher is trying to publish to a queue that is full
ErrProcessorQueueIsFull = errors.New("cannot push new payload since queue is full")
//ErrTopicBufferIsFull is when a Publisher is trying to publish to a Topic that has a full buffer
ErrTopicBufferIsFull = errors.New("cannot push new payload since topic queue is full")
//IDCounter is used to make sure no Topic are generated with a ID that already exists
IDCounter uint = 1
)
// DefaultEngine is the default Pub/Sub engine that Go4Data uses
// It's a channnel based in-memory pubsub system.
type DefaultEngine struct {
// Topics is a container for topics that has been created.
// A topic is automatically created when a Processor registers as a Subscriber to it
Topics sync.Map
}
// Topic is a topic that processors can publish or subscribe to
type Topic struct {
// Key is a string value of the topic
Key string
// ID is a unique ID
ID uint
// Subscribers is a datapipe to all processors that has Subscribed
Subscribers []*Pipe
// Buffer is a data pipe containing our Buffer data. It will empty as soon as a subscriber registers
Buffer *Pipe
sync.Mutex
}
// newID is used to generate a new ID
func newID() uint {
IDCounter++
return IDCounter - 1
}
// EngineAsDefaultEngine will convert the engine to a DefaultEngine
// This is usaully just needed in tests
func EngineAsDefaultEngine() (*DefaultEngine, error) {
conv, ok := engine.(*DefaultEngine)
if ok {
return conv, nil
}
return nil, errors.New("Failed to convert engine to defaultEngine")
}
// WithDefaultEngine is a DialOption that will make the DefaultEngine
// Drain the Buffer each X Second in the background
func WithDefaultEngine(seconds int) DialOptions {
return func(e Engine) (Engine, error) {
de := &DefaultEngine{
Topics: sync.Map{},
}
go func() {
timer := time.NewTicker(time.Duration(seconds) * time.Second)
for {
select {
case <-timer.C:
de.DrainTopicsBuffer()
}
}
}()
engine = de
return de, nil
}
}
// NewTopic will generate a new Topic and assign it into the Topics map, it will also return it
func (de *DefaultEngine) NewTopic(key string) (*Topic, error) {
if de.TopicExists(key) {
return nil, ErrTopicAlreadyExists
}
t := &Topic{
Key: key,
ID: newID(),
Subscribers: make([]*Pipe, 0),
Buffer: &Pipe{
Flow: make(chan payload.Payload, 1000),
},
}
de.Topics.Store(key, t)
return t, nil
}
// TopicExists is used to find out if a topic exists
// will return true if it does, false if not
func (de *DefaultEngine) TopicExists(key string) bool {
if _, ok := de.Topics.Load(key); ok {
return true
}
return false
}
// getTopic is a help util that does the type assertion for us so we dont have to repeat
func (de *DefaultEngine) getTopic(key string) (*Topic, error) {
t, ok := de.Topics.Load(key)
if !ok {
return nil, ErrNoSuchTopic
}
topic, ok := t.(*Topic)
if !ok {
return nil, ErrIsNotTopic
}
return topic, nil
}
// Subscribe will take a key and a Pid (processor ID) and Add a new Subscription to a topic
// It will also return the topic used
func (de *DefaultEngine) Subscribe(key string, pid uint, queueSize int) (*Pipe, error) {
top, err := de.NewTopic(key)
if errors.Is(err, ErrTopicAlreadyExists) {
// Topic exists, see if PID is not duplicate
topic, err := de.getTopic(key)
if err != nil {
return nil, err
}
for _, sub := range topic.Subscribers {
if sub.Pid == pid {
return nil, ErrPidAlreadyRegistered
}
}
top = topic
}
// Topic is new , add subscription
sub := NewPipe(key, pid, queueSize)
top.Lock()
top.Subscribers = append(top.Subscribers, sub)
top.Unlock()
return sub, nil
}
// Unsubscribe will remove and close a channel related to a subscription
func (de *DefaultEngine) Unsubscribe(key string, pid uint) error {
if !de.TopicExists(key) {
return ErrNoSuchTopic
}
topic, err := de.getTopic(key)
if err != nil {
return err
}
topic.Lock()
defer topic.Unlock()
pipeline, err := de.removePipeIfExist(key, pid, topic.Subscribers)
if err != nil {
return err
}
if pipeline != nil {
topic.Subscribers = pipeline
}
return nil
}
// removePipeIfExist is used to delete a index from a pipe slice and return a new slice without it
func (de *DefaultEngine) removePipeIfExist(key string, pid uint, pipes []*Pipe) ([]*Pipe, error) {
for i, p := range pipes {
if p.Pid == pid {
close(p.Flow)
pipes[i] = pipes[len(pipes)-1]
return pipes[:len(pipes)-1], nil
}
}
return nil, ErrNoSuchPid
}
// DrainTopicsBuffer will itterate all topics and drain their buffer if there is any subscribers
func (de *DefaultEngine) DrainTopicsBuffer() {
de.Topics.Range(func(key, value interface{}) bool {
top, ok := value.(*Topic)
if !ok {
return ok
}
top.Lock()
defer top.Unlock()
xCanReceive := len(top.Subscribers)
for len(top.Buffer.Flow) > 0 {
// If no subscriber can Receive more data, stop draining
if xCanReceive == 0 {
break
}
payload := <-top.Buffer.Flow
for _, sub := range top.Subscribers {
select {
case sub.Flow <- payload:
// Managed to send item
default:
// The pipe is full
xCanReceive--
}
}
}
return true
})
}
// Publish is used to publish a payload onto a Topic
// If there is no Subscribers it will push the Payloads onto a Topic Buffer which will be drained as soon
// As there is a subscriber
func (de *DefaultEngine) Publish(key string, payloads ...payload.Payload) []PublishingError {
var errors []PublishingError
var top *Topic
if de.TopicExists(key) {
topic, err := de.getTopic(key)
if err != nil {
return append(errors, PublishingError{
Err: err,
Payload: nil,
})
}
top = topic
} else {
top, _ = de.NewTopic(key)
}
// If Subscribers is empty, add to Buffer
top.Lock()
defer top.Unlock()
for _, payload := range payloads {
if len(top.Subscribers) == 0 {
select {
case top.Buffer.Flow <- payload:
// Managed to send item
default:
// The pipe is full
errors = append(errors, PublishingError{
Err: ErrTopicBufferIsFull,
Payload: payload,
Tid: top.ID,
})
}
} else {
for _, sub := range top.Subscribers {
select {
case sub.Flow <- payload:
// Managed to send
continue
default:
// This Subscriber queue is full, return an error
// We Could send items to the Buffer top.Buffer.Flow <- payload
// But we would need a way of Knowing what Subscriber has gotten What payload to avoid resending
// It to all Subscribers
errors = append(errors, PublishingError{
Err: ErrProcessorQueueIsFull,
Pid: sub.Pid,
Tid: top.ID,
Payload: payload,
})
}
}
}
}
return errors
}
// PublishTopics is used to publish to many topics at once
func (de *DefaultEngine) PublishTopics(topics []string, payloads ...payload.Payload) []PublishingError {
var errors []PublishingError
for _, topic := range topics {
t := topic
errs := de.Publish(t, payloads...)
if errs != nil {
errors = append(errors, errs...)
}
}
if len(errors) == 0 {
return nil
}
return errors
}Once I’ve changed this. I can now run the tests for all the Go4Data packages and hope nothing breaks.
Remember, this is possible since the other packages rely on the Pub/Sub package to expose the 3 methods in the Engine interface. What the methods does don’t matter, as long as they fulfill the design pattern.
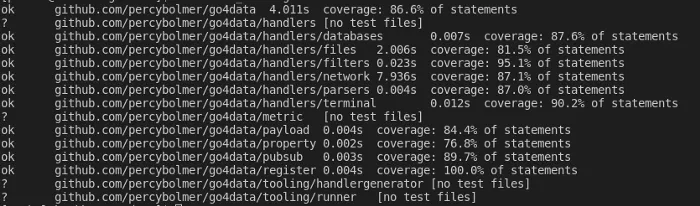
Great, now that we know using the exposed methods that wrap our engine works. We can start implementing a Redis engine.
Implementing the RedisEngine
Now the next step is to create a new struct that fulfills the Engine interface. This one will have a helper function called WithRedisEngine that changes the engine variable to a Redis connection instead of the DefaultEngine.
If your not familiar with Redis you can read my article about using it as a Pub/Sub here.
The simple implementation of Redis instead of the custom built Pub/Sub
package pubsub
import (
"context"
"errors"
"github.com/go-redis/redis/v8"
"github.com/percybolmer/go4data/payload"
)
// RedisEngine is a way to use the Redis Pub/Sub instead of the Default
// Use this if you want to scale the Go4Data into multiple instances and share work
// Between more nodes
type RedisEngine struct {
Options *redis.Options
Client *redis.Client
}
var (
//ErrNoRedisClientConfigured is thrown when the RedisEngine client is nil
ErrNoRedisClientConfigured = errors.New("the redis client in the engine is nil")
// ErrRedisSubscriptionIsNil is when the redisclient returns nil from Subscribe
ErrRedisSubscriptionIsNil = errors.New("the return from Subscribe was nil")
)
// WithRedisEngine will configure the Pub/Sub to use Redis instead
func WithRedisEngine(opts *redis.Options) DialOptions {
return func(e Engine) (Engine, error) {
re := &RedisEngine{}
// Connect to Redis
client := redis.NewClient(opts)
// Ping to make sure connection works
err := client.Ping(context.Background()).Err()
if err != nil {
return nil, err
}
re.Client = client
engine = re
return re, nil
}
}
// Subscribe will subscribe to a certain Redis channel
func (re *RedisEngine) Subscribe(key string, pid uint, queueSize int) (*Pipe, error) {
if re.Client == nil {
return nil, ErrNoRedisClientConfigured
}
ctx := context.Background()
subscription := re.Client.Subscribe(ctx, key)
if subscription == nil {
return nil, ErrRedisSubscriptionIsNil
}
// Grab the Channel that we will use for our Pipe
channel := subscription.Channel()
// This needs some trick to it, Channel will return a []byte, but we want Payloads
// Best solution I can come up with is a Goroutine that transfers from one channel to another..
// This isn't optimal, since we need to force BasePayload...
// Maybe Another refactor is needed in the future
// Where Instead of returnning a Pipe we return a Chan interface
pipe := &Pipe{
Flow: make(chan payload.Payload, queueSize),
Topic: key,
}
go func() {
for msg := range channel {
bp := &payload.BasePayload{}
err := bp.UnmarshalBinary([]byte(msg.Payload))
if err != nil {
// Bad Payloads? Send Errors as Payloads?....
} else {
pipe.Flow <- bp
}
}
}()
return pipe, nil
}
// Publish will push payloads onto the Redis topic
func (re *RedisEngine) Publish(key string, payloads ...payload.Payload) []PublishingError {
var errors []PublishingError
if re.Client == nil {
errors := append(errors, PublishingError{
Err: ErrNoRedisClientConfigured,
})
return errors
}
for _, pay := range payloads {
data, err := pay.MarshalBinary()
if err != nil {
errors = append(errors, PublishingError{
Err: err,
Payload: pay,
})
continue
}
err = re.Client.Publish(context.Background(), key, data).Err()
if err != nil {
errors = append(errors, PublishingError{
Err: err,
Payload: pay,
})
continue
}
}
return errors
}
// PublishTopics is used to publish to many topics at the same time
func (re *RedisEngine) PublishTopics(topics []string, payloads ...payload.Payload) []PublishingError {
var errors []PublishingError
// Itterate all Topics and publish payloads onto all of them
for _, topic := range topics {
t := topic
errs := re.Publish(t, payloads...)
if errs != nil {
errors = append(errors, errs...)
}
}
if len(errors) == 0 {
return nil
}
return errors
}This is only 128 lines of code to replace the whole Pub/Sub engine for the whole project, very nice!
Also since we are using an interface to do this, it’s very simple for us to keep adding Pub/Sub engines if we wanted to try others, maybe Kafka or RabbitMQ?
And why would we want to add others you ask? Because it’s blazing fun!
Now that we have two implementations we can also benchmark them.
The Benchmark
Benchmarking can be hard. Limiting them so that you only test what you want to can be hard. I’m really bad at it, but I will do my best. We want to remove the initialization of the objects that we will push since that’s not what we want to test, so I’ll put that in the init function to run before the tests. We want to test the time it takes to Publish and the time it takes to Publish and until a Subscriber has all the items.
The engines will be created at startup with Go4Data, so let’s also put the connection and initialization of the Engines in the init. Their performance won’t be critical since they are running at startup, so let’s focus on the run time performance. Before running my benchmark I need to setup a Redis instance to use.
sudo docker run --name redis -p 6379:6379 -d redisSo the idea here is that we want to first try benchmarking how fast we can publish data, so one benchmark will only use both engines and publish N amount of items. I will use 100, 1000 and 100000 for my benchmark to see low and high amounts. These benchmarks will be named BenchmarkEnginePubXAmount.
I will also have an benchmark which will test publishing and waiting for the subscriber to receive all items published. Those benchmarks will be named BenchmarkEnginePubSubXAmount.
In Go, you can set the number of times the benchmarks should run, and grab the average on those amounts. In my case I will stick to running each benchmark once, this is because Redis doesn’t seem to like being run down by connections up and down at a high rate. This is done by adding the flag -benchtime=1x.
Here is how the Benchmarks looks. The result of the benchmarking functions for both publish and pub/sub.
package pubsub
import (
"testing"
"github.com/go-redis/redis/v8"
"github.com/percybolmer/go4data/payload"
)
// We create the redisEngine to avoid including connection time during the tests
var redisEngine Engine
var defaultEngine Engine
// Also some Slices with preset data
var hundredthousanPayloads []payload.Payload
var thousandPayloads []payload.Payload
var onehundred []payload.Payload
func init() {
// Initialize all needed items before tests in here
var err error
redisEngine, err = NewEngine(WithRedisEngine(&redis.Options{
Addr: "localhost:6379",
Password: "",
DB: 0,
}))
if err != nil {
panic(err)
}
defaultEngine, err = NewEngine(WithDefaultEngine(10))
if err != nil {
panic(err)
}
hundredthousanPayloads = generatePayloads(100000)
thousandPayloads = generatePayloads(1000)
onehundred = generatePayloads(100)
}
// generatePayloads is used to generate payloads at startup to avoid calculating this inside the benchmark
func generatePayloads(amount int) []payload.Payload {
payloads := make([]payload.Payload, amount)
for n := 0; n < amount; n++ {
payloads[n] = payload.NewBasePayload([]byte(`Test payload`), "benchmarking", nil)
}
return payloads
}
// BenchmarkDefaultEnginePubSub1000000 will take 1000000 payloads and Publish them and see if the Subscriber has received all items
func BenchmarkDefaultEnginePubSub100000(b *testing.B) {
// Start DefaultEngine and Publish 1000 Payloads
benchmarkDefaultEnginePubSub(hundredthousanPayloads, b)
}
// BenchmarkDefaultEnginePubSub1000 will take 1000 payloads and Publish them and see if the Subscriber has received all items
func BenchmarkDefaultEnginePubSub1000(b *testing.B) {
// Start DefaultEngine and Publish 1000 Payloads
benchmarkDefaultEnginePubSub(thousandPayloads, b)
}
// BenchmarkDefaultEnginePubSub100 will take 100 payloads and Publish them and see if the Subscriber has received all items
func BenchmarkDefaultEnginePubSub100(b *testing.B) {
benchmarkDefaultEnginePubSub(onehundred, b)
}
// This benchmark function is used to Test the time for both Publishing and regathering the total amount published.
func benchmarkDefaultEnginePubSub(payloads []payload.Payload, b *testing.B) {
//for n := 0; n < b.N; n++ {
pipe, err := defaultEngine.Subscribe("benchmark", newID(), 100000)
if err != nil {
b.Fatal(err)
}
defaultEngine.Publish("benchmark", payloads...)
for len(pipe.Flow) != len(payloads) {
}
//}
}
// BenchmarkDefaultEnginePub1000000 will take 1000000 payloads and Publish
func BenchmarkDefaultEnginePub100000(b *testing.B) {
// Start DefaultEngine and Publish 1000 Payloads
benchmarkDefaultEnginePub(hundredthousanPayloads, b)
}
// BenchmarkDefaultEnginePub1000 will take 1000 payloads and Publish
func BenchmarkDefaultEnginePub1000(b *testing.B) {
// Start DefaultEngine and Publish 1000 Payloads
benchmarkDefaultEnginePub(thousandPayloads, b)
}
// BenchmarkDefaultEnginePub100 will take 100 payloads and Publish
func BenchmarkDefaultEnginePub100(b *testing.B) {
benchmarkDefaultEnginePub(onehundred, b)
}
// this benchmark is used to test the time for only Publishing
func benchmarkDefaultEnginePub(payloads []payload.Payload, b *testing.B) {
for n := 0; n < b.N; n++ {
defaultEngine.Publish("benchmark", payloads...)
}
}
// BenchmarkRedisEnginePub100000 will Publish 1000000 items onto redis and time it
func BenchmarkRedisEngine100000(b *testing.B) {
benchmarkRedisEnginePub(hundredthousanPayloads, b)
}
// BenchmarkRedisEnginePub1000 will Publish 1000 items onto redis and time it
func BenchmarkRedisEngine1000(b *testing.B) {
benchmarkRedisEnginePub(thousandPayloads, b)
}
// BenchmarkRedisEnginePub100 will Publish 100 items onto redis and time it
func BenchmarkRedisEngine100(b *testing.B) {
benchmarkRedisEnginePub(onehundred, b)
}
// benchmarkRedisEnginePub will Publish X items onto redis and time it
func benchmarkRedisEnginePub(payloads []payload.Payload, b *testing.B) {
for n := 0; n < b.N; n++ {
redisEngine.Publish("benchmark", payloads...)
}
}
// BenchmarkRedisEnginePubSub100000 will Publish 1000000 items onto redis and time it and Subscribe to the output aswell
func BenchmarkRedisEnginePubSub100000(b *testing.B) {
benchmarkRedisEnginePubSub(hundredthousanPayloads, b)
}
// BenchmarkRedisEnginePubSub1000 will Publish 1000 items onto redis and time it and Subscribe to the output aswell
func BenchmarkRedisEnginePubSub1000(b *testing.B) {
benchmarkRedisEnginePubSub(thousandPayloads, b)
}
// BenchmarkRedisEnginePubSub100 will Publish 100 items onto redis and time it and Subscribe to the output aswell
func BenchmarkRedisEnginePubSub100(b *testing.B) {
benchmarkRedisEnginePubSub(onehundred, b)
}
// benchmarkRedisEnginePubSub will Publish X items onto redis and wait until subscriber has them all
func benchmarkRedisEnginePubSub(payloads []payload.Payload, b *testing.B) {
//for n := 0; 0 < b.N; n++ {
pipe, err := redisEngine.Subscribe("benchmark", newID(), 1000000)
if err != nil {
b.Fatal(err)
}
defer redisEngine.Cancel()
redisEngine.Publish("benchmark", payloads...)
for len(pipe.Flow) != len(payloads) {
}
//}
}As you can see benchmarking in Go is rather easy, it’s writing good benchmarks that are hard, and I’m still trying to learn. We can simply run this benchmark using the go test -bench command.
Benchmarking result from DefaultEngine and RedisEngine.
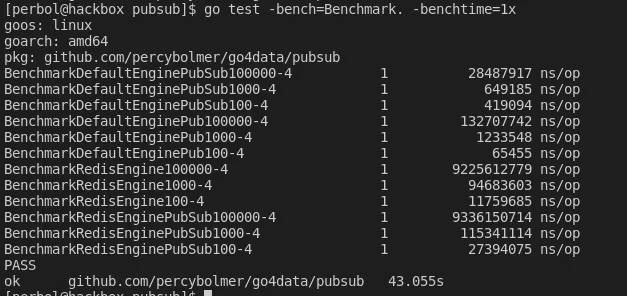
The output from the benchmark shows the name first, the number of benchmarks ran, and the nanoseconds per operation (ns/op).
As expected, DefaultEngine runs faster than Redis. This is expected since the DefaultEngine runs in the memory used by the application, so it has direct access. The advantage of Redis is that it provides persistence and the ability to now run Go4Data across multiple nodes.
Now users are allowed to easily replace a big part of the project since we leverage the power of interfaces.
That’s it for this time. Thank you for reading!
If you enjoyed my writing, please support future articles by buying me an Coffee