We Measure the Power of Cars, Computers, and Cellphones. But What About Code?
A deep dive into benchmarking in Golang
by Percy Bolmér, February 12, 2021

I’m not going to lie — benchmarking is not one of my biggest strengths. I don’t do it nearly as often as I’d like. But it’s become more frequent since I started using Go as my primary language of choice. One of the reasons for this is because Go has some great built-in support for benchmarking.
Go lets us developers benchmark using the testing package. So the testing package comes with benchmarking powers included. That’s awesome!
In this article, I want to dive deeper into benchmarks, but I’ll start from scratch. After reading this, I hope I’ve provided you with a slightly better understanding of benchmarks.
Let’s start talking about benchmarking. Benchmarking in software development is about testing the performance of the code we write.
“A benchmark is the act of running a computer program , a set of programs, or other operations, in order to assess the relative performance of an object.”— Wikipedia
Benchmarking allows us to take different solutions and try their performance, comparing the measured speeds. This is great knowledge to possess as a developer, especially when you have an application you need to speed up and optimize.
It’s important to remember a golden rule in development: Never optimize prematurely. Just because we’ll learn how to benchmark doesn’t mean I suggest running and benchmarking every piece of code you have. I strongly feel that benchmarking is a tool to use when you face performance issues or when pure curiosity is killing you.
“Premature optimization is the root of all evil.” — Donald E. Knuth, “The Art of Computer Programming”
It’s not uncommon to see posts on the internet from junior developers about different code solutions, asking which one is best. But saying something is the best when talking about code is something I prefer not to do.
Let’s stick to the expression most performant since sometimes slower code is more easily maintained and readable. Thus, that code is better, if you ask me, unless you’re faced with performance issues, of course.
Let’s begin learning how to benchmark using Go. I’ve gathered some questions from a junior developer that I couldn’t answer related to performance.
We’ll take a look at them for him.
- Are slices or maps faster?
- Is the speed of slices and maps affected by size?
- Does the key type used within maps matter?
Writing a Super Simple Benchmark
Before solving the questions, I’ll start by building a simple benchmark and showcasing how a benchmark is done with Go. After we know how to do that, let’s evolve it to unravel the answers needed.
I’ve created a new project for these benchmarks, and I recommend you do the same so you can try it yourself. You’ll need to create a directory and run:
go mod init benchingYou also need to create a file ending with _test.go . In my case, it’s benching_test.go .
Benchmarks in Go are done with the testing package, much like regular unit tests. Just like unit tests, benchmarks are triggered with the same Go test tooling.
The Go tool will know what methods are benchmarks based on their names. Any method starting with Benchmark that accepts a pointer to testing.B will be running as a benchmark.
package benching
import (
"testing"
)
func BenchmarkSimplest(b *testing.B) {
}Try it out by running the go test command with the -bench=. flag.
By running ‘go test -bench=.’ and seeing an output, we know the benchmark works
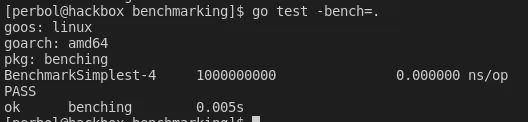
Let’s stop here for a while and reflect on the output. Each benchmark that’s executed will output three values: the name, the number of times the benchmark ran, and the ns/op .
The name is pretty self-explanatory. It’s the name we set in the test file.
The number of times the benchmark is executed is interesting. Each benchmark is executed multiple times, and each execution is timed. The execution time is then averaged based on the number of times it ran. This is nice since running the benchmark once would provide bad statistical correctness.
The ns/op stands for nanoseconds/operation. It’s the time the method call took.
If you have multiple benchmarks and only want to run one or a few, you can replace the dot with a string, matching the names like -bench=BenchmarkSimplest . Remember that saying -bench=Benchmark will still trigger our benchmark since the string matches the beginning of the method.
Replacing the ‘-bench=’ value can be used to specify what benchmarks to run

So right now we can benchmark the speed, but this might not always be everything we want to measure. Thankfully, if we take a look in the testing package , we can find that adding the -benchmem flag will add information about bytes allocated per operation (B/op) and allocations per operation (allocs/op).
If you’re not familiar with allocations and memory, I can suggest an article by
Vincent Blanchon
Adding the ‘-benchmem’ flag adds B/op and allocs/op

We’re soon ready to start benchmarking real things — just bear with me a few more moments. What’s up with the input parameter in our benchmark, *testing.B ? Let’s take a look at the definition of it in the standard library to learn what we’re dealing with.
// B is a type passed to Benchmark functions to manage benchmark
// timing and to specify the number of iterations to run.
//
// A benchmark ends when its Benchmark function returns or calls any of the methods
// FailNow, Fatal, Fatalf, SkipNow, Skip, or Skipf. Those methods must be called
// only from the goroutine running the Benchmark function.
// The other reporting methods, such as the variations of Log and Error,
// may be called simultaneously from multiple goroutines.
//
// Like in tests, benchmark logs are accumulated during execution
// and dumped to standard output when done. Unlike in tests, benchmark logs
// are always printed, so as not to hide output whose existence may be
// affecting benchmark results.
type B struct {
common
importPath string // import path of the package containing the benchmark
context *benchContext
N int
previousN int // number of iterations in the previous run
previousDuration time.Duration // total duration of the previous run
benchFunc func(b *B)
benchTime benchTimeFlag
bytes int64
missingBytes bool // one of the subbenchmarks does not have bytes set.
timerOn bool
showAllocResult bool
result BenchmarkResult
parallelism int // RunParallel creates parallelism*GOMAXPROCS goroutines
// The initial states of memStats.Mallocs and memStats.TotalAlloc.
startAllocs uint64
startBytes uint64
// The net total of this test after being run.
netAllocs uint64
netBytes uint64
// Extra metrics collected by ReportMetric.
extra map[string]float64
}Testing.B is a struct holding any data related to the running benchmark. It also holds a struct called BenchmarkResult , which is used to format the output. If there’s anything in the output you don’t fully understand, I strongly suggest opening benchmark.go and reading the code.
One important thing to notice is the N variable. Remember how benchmarks are executed many times? How many times benchmarks are performed is specified by the N variable inside testing.B.
According to the documentation, this needs to be accounted for in the benchmarks, so let’s update BenchmarkSimplest to account for N.
// BenchmarkSimplestNTimes runs a benchmark N amount of times.
func BenchmarkSimplestNTimes(b *testing.B) {
for i := 0; i < b.N; i++ {
// Run function to benchmark here
}
}We’ve updated it by making a for loop that’ll iterate N times. When I benchmark, I like to set the N to specific values, so I make sure my benchmarks are fair. Otherwise, one benchmark may run 100,000 times, and another one might run twice.
This can be done by adding the -benchtime= flag. The input is either seconds or X amount of times, so to force benchmarks to be executed 100 times, we can set it to -benchtime=100x.

Ready, Set, Benchmark!
It’s time to start testing and answering the earlier questions about performance.
- Are slices or maps faster?
- Is the speed of slices and maps affected by size?
- Does the key used matter?
I’ll start implementing a benchmark for inserting data into maps and slices and then another benchmark for reading data back. A trick I’ve stolen from Dave Cheney is to create a method that takes input parameters that we want to benchmark — this makes benchmarking many different values very easy.
// insertXIntMap is used to add X amount of items into a Map[int]int
func insertXIntMap(x int, b *testing.B) {
// Initialize Map and Insert X amount of items
testmap := make(map[int]int, 0)
// Reset timer after Initalizing map, that's not what we want to test
b.ResetTimer()
for i := 0; i < x; i++ {
// Insert value of I into I key.
testmap[i] = i
}
}This method will take an integer value of how many integers to insert into the map. This is so we can test if the size of the map affects the insert performance. This method will be executed by our benchmarks. I’ll also create multiple benchmark functions that each inserts a different integer to benchmark.
// BenchmarkInsertIntMap100000 benchmarks the speed of inserting 100000 integers into the map.
func BenchmarkInsertIntMap100000(b *testing.B) {
for i := 0; i < b.N; i++ {
insertXIntMap(100000, b)
}
}
// BenchmarkInsertIntMap10000 benchmarks the speed of inserting 10000 integers into the map.
func BenchmarkInsertIntMap10000(b *testing.B) {
for i := 0; i < b.N; i++ {
insertXIntMap(10000, b)
}
}
// BenchmarkInsertIntMap1000 benchmarks the speed of inserting 1000 integers into the map.
func BenchmarkInsertIntMap1000(b *testing.B) {
for i := 0; i < b.N; i++ {
insertXIntMap(1000, b)
}
}
// BenchmarkInsertIntMap100 benchmarks the speed of inserting 100 integers into the map.
func BenchmarkInsertIntMap100(b *testing.B) {
for i := 0; i < b.N; i++ {
insertXIntMap(100, b)
}
}See how I reuse the same method in each benchmark but just modify the number of inserts? That’s a neat trick since we can easily test large and small amounts.

So the amount of time goes up — this is as expected since we’re increasing the number of insertions. This doesn’t tell us much yet since we need something to compare the results with. We can take the time to answer one question, though: Does the key type used within maps matter?
I’m going to copy all of the methods and replace the key type used with an interface instead. To make things easier, I’ll have two files now, benching_map_interface_test.go and benching_map_int_test.go . The benchmark methods will correlate to the name — this is just to maintain an easily navigable structure when we add more benchmarks.
package benching
import (
"testing"
)
// insertXInterfaceMap is used to add X amount of items into a Map[interface]int
func insertXInterfaceMap(x int, b *testing.B) {
// Initialize Map and Insert X amount of items
testmap := make(map[interface{}]int, 0)
// Reset timer after Initalizing map, that's not what we want to test
b.ResetTimer()
for i := 0; i < x; i++ {
// Insert value of I into I key.
testmap[i] = i
}
}
// BenchmarkInsertInterfaceMap1000000 benchmarks the speed of inserting 1000000 integers into the map.
func BenchmarkInsertInterfaceMap1000000(b *testing.B) {
for i := 0; i < b.N; i++ {
insertXInterfaceMap(1000000, b)
}
}
// BenchmarkInsertInterfaceMap100000 benchmarks the speed of inserting 100000 integers into the map.
func BenchmarkInsertInterfaceMap100000(b *testing.B) {
for i := 0; i < b.N; i++ {
insertXInterfaceMap(100000, b)
}
}
// BenchmarkInsertInterfaceMap10000 benchmarks the speed of inserting 10000 integers into the map.
func BenchmarkInsertInterfaceMap10000(b *testing.B) {
for i := 0; i < b.N; i++ {
insertXInterfaceMap(10000, b)
}
}
// BenchmarkInsertInterfaceMap1000 benchmarks the speed of inserting 1000 integers into the map.
func BenchmarkInsertInterfaceMap1000(b *testing.B) {
for i := 0; i < b.N; i++ {
insertXInterfaceMap(1000, b)
}
}
// BenchmarkInsertInterfaceMap100 benchmarks the speed of inserting 100 integers into the map.
func BenchmarkInsertInterfaceMap100(b *testing.B) {
for i := 0; i < b.N; i++ {
insertXInterfaceMap(100, b)
}
}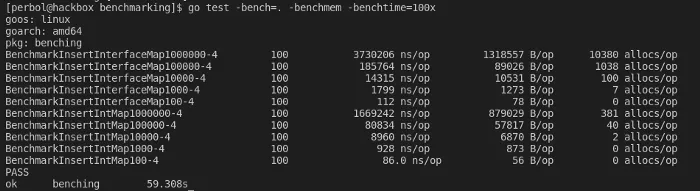
I think we found the answer to at least one question so far. The key type does seem to matter, as we can see based on the result. Using an Int instead of an Interfaceas the key is 2.23x times faster in this benchmark, considering the1000000` benchmark. However, I don’t think I’ve ever seen an interface being used as a key before.
The doubling of performance based on keys seems to match a conclusion I’ve read by Jason Moiron
- Are slices or maps faster?
- Is the speed of slices and maps affected by size?
- D̸o̸e̸s̸ ̸t̸h̸e̸ ̸ke̸y̸ ̸t̸y̸p̸e̸ ̸u̸s̸e̸d̸ ̸i̸n̸ ̸m̸a̸p̸s̸ ̸m̸a̸t̸t̸e̸r̸? Yes, it does.
Before we move on, I’d like to take a moment and also add a new benchmark since it’s fun. In the benchmarks we ran just now, the maps weren’t preallocated in size. So we can change that and benchmark the difference.
What we have to change is the insertXIntMap method, and we also have to change the initialization of the map to use the length of X instead. I’ve created one new file, benching_map_prealloc_int_test.go , and in it I’ve changed the insertXIntMap method to initialize the size beforehand.
// insertXPreallocIntMap is used to add X amount of items into a Map[int]int
func insertXPreallocIntMap(x int, b *testing.B) {
// Initialize Map and Insert X amount of items and Prealloc the size to X
testmap := make(map[int]int, x)
// Reset timer after Initalizing map, that's not what we want to test
b.ResetTimer()
for i := 0; i < x; i++ {
// Insert value of I into I key.
testmap[i] = i
}
}Remember how I said we can control what benchmarks to run using the -bench= flag? It’s time to use this trick because now we have many benchmarks. But for this particular benchmark, I’m only interested in comparing a map without a set size and a map with a preallocated size.
I’ve named my new benchmarks BenchmarkInsertIntMapPrealloc , so they share the same name as B enchmarkInsertIntMap . We can use that as our trigger. This new benchmark file is an exact copy of the other IntMap benchmark — I’ve only changed the names and the method to run.
package benching
import (
"testing"
)
// insertXPreallocIntMap is used to add X amount of items into a Map[int]int
func insertXPreallocIntMap(x int, b *testing.B) {
// Initialize Map and Insert X amount of items and Prealloc the size to X
testmap := make(map[int]int, x)
// Reset timer after Initalizing map, that's not what we want to test
b.ResetTimer()
for i := 0; i < x; i++ {
// Insert value of I into I key.
testmap[i] = i
}
}
// BenchmarkInsertIntMapPreAlloc1000000 benchmarks the speed of inserting 1000000 integers into the map.
func BenchmarkInsertIntMapPreAlloc1000000(b *testing.B) {
for i := 0; i < b.N; i++ {
insertXPreallocIntMap(1000000, b)
}
}
// BenchmarkInsertIntMapPreAlloc100000 benchmarks the speed of inserting 100000 integers into the map.
func BenchmarkInsertIntMapPreAlloc100000(b *testing.B) {
for i := 0; i < b.N; i++ {
insertXPreallocIntMap(100000, b)
}
}
// BenchmarkInsertIntMapPreAlloc10000 benchmarks the speed of inserting 10000 integers into the map.
func BenchmarkInsertIntMapPreAlloc10000(b *testing.B) {
for i := 0; i < b.N; i++ {
insertXPreallocIntMap(10000, b)
}
}
// BenchmarkInsertIntMapPreAlloc1000 benchmarks the speed of inserting 1000 integers into the map.
func BenchmarkInsertIntMapPreAlloc1000(b *testing.B) {
for i := 0; i < b.N; i++ {
insertXPreallocIntMap(1000, b)
}
}
// BenchmarkInsertIntMapPreAlloc100 benchmarks the speed of inserting 100 integers into the map.
func BenchmarkInsertIntMapPreAlloc100(b *testing.B) {
for i := 0; i < b.N; i++ {
insertXPreallocIntMap(100, b)
}
}Let’s run the benchmark and change the bench flag.
go test -bench=BenchmarkInsertIntMap -benchmem -benchtime=100xDifference between a preallocated size in a map
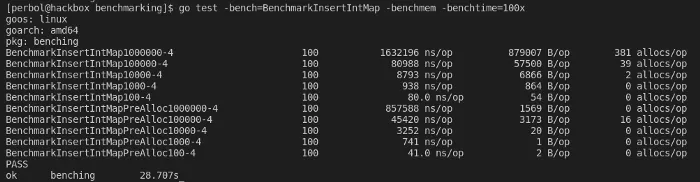
This benchmark shows us that setting the size of the map has quite a big impact. It actually is when you see the 1000000 test has a difference of 1.92x times the performance. And look at the bytes allocated (B/op) — much nicer.
Let’s move onto implementing the insertion benchmark for slices. It’ll be a copy of the map implementation but using a slice this time with append .
I’m also going to be creating benchmarks for preallocated slices and benchmarks for nonallocated sizes since that was a lot of fun. We can just recreate the insertX method, copy-paste everything, and then search for Map and replace it with Slice.
// insertXIntSlice is used to add X amount of items into a []int
func insertXIntSlice(x int, b *testing.B) {
// Initalize a Slice and insert X amount of Items
testSlice := make([]int, 0)
// reset timer
b.ResetTimer()
for i := 0; i < x; i++ {
testSlice = append(testSlice, i)
}
}package benching
import (
"testing"
)
// insertXIntSlice is used to add X amount of items into a []int
func insertXIntSlice(x int, b *testing.B) {
// Initalize a Slice and insert X amount of Items
testSlice := make([]int, 0)
// reset timer
b.ResetTimer()
for i := 0; i < x; i++ {
testSlice = append(testSlice, i)
}
}
// BenchmarkInsertIntSlice1000000 benchmarks the speed of inserting 1000000 integers into the Slice.
func BenchmarkInsertIntSlice1000000(b *testing.B) {
for i := 0; i < b.N; i++ {
insertXIntSlice(1000000, b)
}
}
// BenchmarkInsertIntSlice100000 benchmarks the speed of inserting 100000 integers into the Slice.
func BenchmarkInsertIntSlice100000(b *testing.B) {
for i := 0; i < b.N; i++ {
insertXIntSlice(100000, b)
}
}
// BenchmarkInsertIntSlice10000 benchmarks the speed of inserting 10000 integers into the Slice.
func BenchmarkInsertIntSlice10000(b *testing.B) {
for i := 0; i < b.N; i++ {
insertXIntSlice(10000, b)
}
}
// BenchmarkInsertIntSlice1000 benchmarks the speed of inserting 1000 integers into the Slice.
func BenchmarkInsertIntSlice1000(b *testing.B) {
for i := 0; i < b.N; i++ {
insertXIntSlice(1000, b)
}
}
// BenchmarkInsertIntSlice100 benchmarks the speed of inserting 100 integers into the Slice.
func BenchmarkInsertIntSlice100(b *testing.B) {
for i := 0; i < b.N; i++ {
insertXIntSlice(100, b)
}
}For the preallocated slice, we don’t want to use append since that adds an index to the slice. So the preallocated one has to be changed to instead use the correct index.
// insertXPreallocIntSlice is used to add X amount of items into a []int
func insertXPreallocIntSlice(x int, b *testing.B) {
// Initalize a Slice and insert X amount of Items
testSlice := make([]int, x)
// reset timer
b.ResetTimer()
for i := 0; i < x; i++ {
testSlice[i] = i
}
}package benching
import (
"testing"
)
// insertXPreallocIntSlice is used to add X amount of items into a []int
func insertXPreallocIntSlice(x int, b *testing.B) {
// Initalize a Slice and insert X amount of Items
testSlice := make([]int, x)
// reset timer
b.ResetTimer()
for i := 0; i < x; i++ {
testSlice[i] = i
}
}
// BenchmarkInsertIntSlicePreAllooc1000000 benchmarks the speed of inserting 1000000 integers into the Slice.
func BenchmarkInsertIntSlicePreAllooc1000000(b *testing.B) {
for i := 0; i < b.N; i++ {
insertXPreallocIntSlice(1000000, b)
}
}
// BenchmarkInsertIntSlicePreAllooc1000000 benchmarks the speed of inserting 100000 integers into the Slice.
func BenchmarkInsertIntSlicePreAllooc100000(b *testing.B) {
for i := 0; i < b.N; i++ {
insertXPreallocIntSlice(100000, b)
}
}
// BenchmarkInsertIntSlicePreAllooc10000 benchmarks the speed of inserting 10000 integers into the Slice.
func BenchmarkInsertIntSlicePreAllooc10000(b *testing.B) {
for i := 0; i < b.N; i++ {
insertXPreallocIntSlice(10000, b)
}
}
// BenchmarkInsertIntSlicePreAllooc1000 benchmarks the speed of inserting 1000 integers into the Slice.
func BenchmarkInsertIntSlicePreAllooc1000(b *testing.B) {
for i := 0; i < b.N; i++ {
insertXPreallocIntSlice(1000, b)
}
}
// BenchmarkInsertIntSlicePreAllooc100 benchmarks the speed of inserting 100 integers into the Slice.
func BenchmarkInsertIntSlicePreAllooc100(b *testing.B) {
for i := 0; i < b.N; i++ {
insertXPreallocIntSlice(100, b)
}
}Now that we’ve finished the slice benchmarks, let’s run them and see the results.
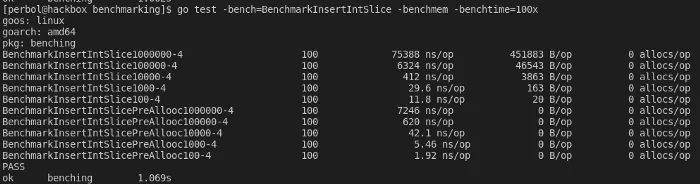
The difference between a preallocated slices and a dynamic slices is huge. The 1000000 benchmarks are 75388 ns/op versus 7246 ns/op . This is a performance difference of 10.4x the speed. Working with fixed-size slices might be troublesome in some cases, though. I usually don’t know the size in my applications as they tend to be dynamic.
It seems that slices outperform maps when it comes to inserting data — on small numbers and bigger numbers. We also need to benchmark how selecting data performs.
To benchmark this, we’ll initialize a slice and map just like we’ve done, add X amount of items, and then reset the timer. We’ll then begin benchmarking how fast we can find X items. I’ve decided to iterate the slice and map using the index value of i . I’ll post the code for both benchmarks below — they’re almost identical.
package benching
import (
"testing"
)
// selectXIntMap is used to Select X amount of times from a map
func selectXIntMap(x int, b *testing.B) {
// Initialize Map and Insert X amount of items
testmap := make(map[int]int, x)
// Reset timer after Initalizing map, that's not what we want to test
for i := 0; i < x; i++ {
// Insert value of I into I key.
testmap[i] = i
}
// holder is a holder that we use to hold the found int, we cannot grab from a map without storing the result
var holder int
b.ResetTimer()
for i := 0; i < x; i++ {
// Select from map
holder = testmap[i]
}
// Compiler wont let us get away with an unused holder, so a quick check will trick the compiler
if holder != 0 {
}
}
// BenchmarkSelectIntMap1000000 benchmarks the speed of selecting 1000000 items from the map.
func BenchmarkSelectIntMap1000000(b *testing.B) {
for i := 0; i < b.N; i++ {
selectXIntMap(1000000, b)
}
}
// BenchmarkSelectIntMap100000 benchmarks the speed of selecting 100000 items from the map.
func BenchmarkSelectIntMap100000(b *testing.B) {
for i := 0; i < b.N; i++ {
selectXIntMap(100000, b)
}
}
// BenchmarkSelectIntMap10000 benchmarks the speed of selecting 10000 items from the map.
func BenchmarkSelectIntMap10000(b *testing.B) {
for i := 0; i < b.N; i++ {
selectXIntMap(10000, b)
}
}
// BenchmarkSelectIntMap1000 benchmarks the speed of selecting 1000 items from the map.
func BenchmarkSelectIntMap1000(b *testing.B) {
for i := 0; i < b.N; i++ {
selectXIntMap(1000, b)
}
}
// BenchmarkSelectIntMap100 benchmarks the speed of selecting 100 items from the map.
func BenchmarkSelectIntMap100(b *testing.B) {
for i := 0; i < b.N; i++ {
selectXIntMap(100, b)
}
}package benching
import (
"testing"
)
// selectXIntSlice is used to Select X amount of times from a Slice
func selectXIntSlice(x int, b *testing.B) {
// Initialize Slice and Insert X amount of items
testSlice := make([]int, x)
// Reset timer after Initalizing Slice, that's not what we want to test
for i := 0; i < x; i++ {
// Insert value of I into I key.
testSlice[i] = i
}
// holder is a holder that we use to hold the found int, we cannot grab from a Slice without storing the result
var holder int
b.ResetTimer()
for i := 0; i < x; i++ {
// Select from Slice
holder = testSlice[i]
}
// Compiler wont let us get away with an unused holder, so a quick check will trick the compiler
if holder != 0 {
}
}
// BenchmarkSelectIntSlice1000000 benchmarks the speed of selecting 1000000 items from the Slice.
func BenchmarkSelectIntSlice1000000(b *testing.B) {
for i := 0; i < b.N; i++ {
selectXIntSlice(1000000, b)
}
}
// BenchmarkSelectIntSlice100000 benchmarks the speed of selecting 100000 items from the Slice.
func BenchmarkSelectIntSlice100000(b *testing.B) {
for i := 0; i < b.N; i++ {
selectXIntSlice(100000, b)
}
}
// BenchmarkSelectIntSlice10000 benchmarks the speed of selecting 10000 items from the Slice.
func BenchmarkSelectIntSlice10000(b *testing.B) {
for i := 0; i < b.N; i++ {
selectXIntSlice(10000, b)
}
}
// BenchmarkSelectIntSlice1000 benchmarks the speed of selecting 1000 items from the Slice.
func BenchmarkSelectIntSlice1000(b *testing.B) {
for i := 0; i < b.N; i++ {
selectXIntSlice(1000, b)
}
}
// BenchmarkSelectIntSlice100 benchmarks the speed of selecting 100 items from the Slice.
func BenchmarkSelectIntSlice100(b *testing.B) {
for i := 0; i < b.N; i++ {
selectXIntSlice(100, b)
}
}Benchmark results comparing maps and slices
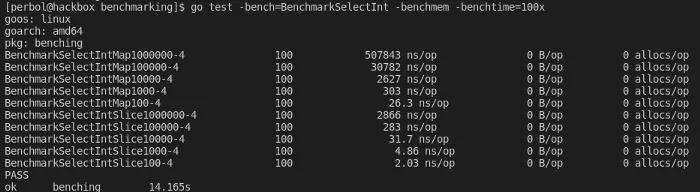
If you noticed, the code for selectXIntSlice and selectXIntMap is the same — the only difference is the make command. The difference in performance for these two is quite obvious, though.
Comparing Benchmark Results
So we have benchmarking numbers now — let’s compile them into a table so it’s easier to review.
Benchmark,Type,ns/op,B/op,allocs/op,Fixed-size
Insert,Map[interface]int,3730206,1318557,10380,no
Insert,Map[int]int,1632196,879007,381,no
Insert,Map[int]int,857588,1569,0,yes
Insert,[]int,75388,451883,0,no
Insert,[]int,7246,0,0,yes
Select,Map[int]int,507843,0,0,yes
Select,[]int,2866,0,0,yesSo how much difference is there between slices and maps?
Slices are faster by a factor of 21.65x (1321196/75388) when comparing the performance of writing into a dynamic size.
Slices are faster by a factor of 118.35x (857588/7246 ) when comparing the performance of writing into a preallocated size.
Slices are faster by a factor of 177.19x (507843/2866) when comparing the performance of reading.
Are slices or maps faster?
Slices seems to outperform maps by far using these benchmarks. The difference is so big that I’m thinking I must have screwed up these benchmarks somehow.
However, maps are easier to use. In these benchmarks we assume we know the indexes in the slice to use. I can think of many cases where we don’t know the index and would probably have to iterate the whole slice, like a map[userID]User instead of a for loop over a []User.
Are the speed of slices and maps affected by size?
Size doesn’t seem to matter in these cases.
Does the key type used within maps matter
Yes, it does. Using an integer proved 2.23x faster than an interface.
Adding a More Realistic Use Case
So slices seem a lot more performant, but I’m going to be honest — I hardly ever know the correct index for my slices. Most of the time, I have to iterate the whole slice to find what I’m searching for. This is the main reason why I often use a map instead.
I’m going to create a benchmark with this use case. We’ll have a map[userID]User and a []User . The benchmark will be a race about finding a certain user.
I’ve created a new file that contains code to generate random users. I’ll generate 10,000, 100,000, and 1 million users in a slice and a map. Imagine if we had an API, the user ID was sent to us, and we wanted to find that user. This is the scenario we’ll test. I’ll also shuffle the slice since this simulates a real use case where data is added dynamically.
I call this benchmark “Saving Private Ryan.” We need to find him, and he has the user ID 7777.
package benching
import (
"math/rand"
"testing"
"time"
)
// Create slices and Maps to use in benchmark so we dont have to recreate them each itteration
var userSlice10000 []User
var userSlice100000 []User
var userSlice1000000 []User
var userMap10000 map[int]User
var userMap100000 map[int]User
var userMap1000000 map[int]User
// Names Some Non-Random name lists used to generate Random Users
var Names []string = []string{"Jasper", "Johan", "Edward", "Niel", "Percy", "Adam", "Grape", "Sam", "Redis", "Jennifer", "Jessica", "Angelica", "Amber", "Watch"}
// SirNames Some Non-Random name lists used to generate Random Users
var SirNames []string = []string{"Ericsson", "Redisson", "Edisson", "Tesla", "Bolmer", "Andersson", "Sword", "Fish", "Coder"}
var IDCounter int
type User struct {
ID int
Name string
}
func init() {
userMap10000 = generateMapUsers(10000)
userMap100000 = generateMapUsers(100000)
userMap1000000 = generateMapUsers(1000000)
userSlice10000 = generateSliceUsers(10000)
userSlice100000 = generateSliceUsers(100000)
userSlice1000000 = generateSliceUsers(1000000)
// Shuffle the slice
rand.Shuffle(len(userSlice10000), func(i, j int) {
userSlice10000[i], userSlice10000[j] = userSlice10000[j], userSlice10000[i]
})
rand.Shuffle(len(userSlice100000), func(i, j int) {
userSlice100000[i], userSlice100000[j] = userSlice100000[j], userSlice100000[i]
})
rand.Shuffle(len(userSlice1000000), func(i, j int) {
userSlice1000000[i], userSlice1000000[j] = userSlice1000000[j], userSlice1000000[i]
})
}
// generateSliceUsers will generate X amount of users in a slice
func generateSliceUsers(x int) []User {
IDCounter = 0
users := make([]User, x)
for i := 0; i <= x; i++ {
users = append(users, generateRandomUser())
}
return users
}
// generateSliceUsers will generate X amount of users in a slice
func generateMapUsers(x int) map[int]User {
IDCounter = 0
users := make(map[int]User, x)
for i := 0; i <= x; i++ {
users[i] = generateRandomUser()
}
return users
}
// generate a RandomUser
func generateRandomUser() User {
rand.Seed(time.Now().UnixNano())
nameMax := len(Names)
sirNameMax := len(SirNames)
nameIndex := rand.Intn(nameMax-1) + 1
sirNameIndex := rand.Intn(sirNameMax-1) + 1
id := IDCounter
IDCounter++
return User{
ID: id,
Name: Names[nameIndex] + " " + SirNames[sirNameIndex],
}
}
// findUserInSlice is used to search a slice of users for a userID
func findUserInSlice(userID int, users []User) {
// Now find the userID provided
for _, user := range users {
if user.ID == userID {
return
}
}
}
// findUserInMap is used to search a Map of users for a particular ID
func findUserInMap(userID int, users map[int]User) {
if _, ok := users[userID]; ok {
return
}
}
// BenchmarkFindUserInSlice1000000 will search in a slice of size 1000000 to find a user ID
func BenchmarkFindUserInSlice1000000(b *testing.B) {
for i := 0; i < b.N; i++ {
findUserInSlice(7777, userSlice1000000)
}
}
// BenchmarkFindUserInSlice100000 will search in a slice of size 100000 to find a user ID
func BenchmarkFindUserInSlice100000(b *testing.B) {
for i := 0; i < b.N; i++ {
findUserInSlice(7777, userSlice100000)
}
}
// BenchmarkFindUserInSlice10000 will search in a slice of size 10000 to find a user ID
func BenchmarkFindUserInSlice10000(b *testing.B) {
for i := 0; i < b.N; i++ {
findUserInSlice(7777, userSlice10000)
}
}
// BenchmarkFindUserInMap1000000 will search in a Map of size 1000000 to find a user ID
func BenchmarkFindUserInMap1000000(b *testing.B) {
for i := 0; i < b.N; i++ {
findUserInMap(7777, userMap1000000)
}
}
// BenchmarkFindUserInMap100000 will search in a Map of size 100000 to find a user ID
func BenchmarkFindUserInMap100000(b *testing.B) {
for i := 0; i < b.N; i++ {
findUserInMap(7777, userMap100000)
}
}
// BenchmarkFindUserInMap10000 will search in a Map of size 10000 to find a user ID
func BenchmarkFindUserInMap10000(b *testing.B) {
for i := 0; i < b.N; i++ {
findUserInMap(7777, userMap100000)
}
}Benchmarking result of finding a user in a map versus a slice
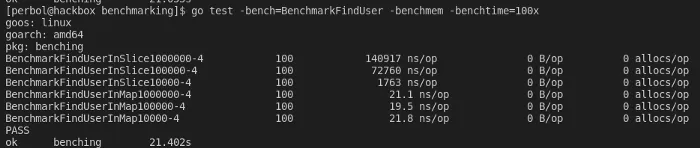
As you can see, the slice no longer outperforms the map. If you look at the result, you’ll see that a map tends to keep the same speed no matter how many items are in it, while a slice takes longer for each item added.
Type,Users,ns/op
Slice,10000,1763
Slice,100000,72760
Slice,100000,140917
Map,10000,21.8
Map,100000,19.5
Map,100000,21.1In this use case, the map is more performant with a factor of 6678.53x (140917 / 21.1).
Conclusion
Are slices or maps faster?
Slices are much more performant when It comes to raw power, but less sophisticated and harder to use — as showcased with our “Saving Private Ryan” benchmark. Sometimes power isn’t everything.
I tend to use maps since they offer easy access to the stored values. As is the case many times in programming, it depends on your use case.
Is the speed of slices and maps affected by size?
Sadly for me, my wife says size does matter. My benchmark says the same. When using the correct index number — sure, it doesn’t matter. But if you don’t know what index your value is stored in, size does matter a lot.
Does the key type used within maps matter?
Yes, it does. Using an integer proved 2.23x faster than an interface.
That’s it for today, I hope you’ve learned something about benchmarking. I know I have for sure. The full code can be found here.
Don’t forget to go out there, and benchmark the world.
If you enjoyed my writing, please support future articles by buying me an Coffee